.png?width=380&height=58&name=Layer_1%20(3).png "Compoze Labs Logo")


 Eric Carr
Eric Carr
Why AI Pilots Don't Make It to Production
Count your active AI pilots. In the organizations we walk into, the number is usually somewhere between 15 and 30. Now name one workflow that runs...

You funded an AI pilot. Your team shipped a proof-of-concept. Six months later, it still isn't in production — and the budget conversation for next quarter is two weeks away.
You're not the outlier. Gartner projects that more than 40% of agentic AI projects will be abandoned by the end of 2027, and earlier guidance from the same analysts put roughly half of GenAI pilots on the same path. The pattern is consistent: pilots that demoed well, scoped poorly, and then quietly missed every production date that followed.
This post is for the buyer six months in — the one staring at a stalled AI initiative and trying to decide whether to refactor, restart, or write it off. The approach below is the one we use at Compoze Labs to rescue pilots that have already burned six figures and a steering committee's patience.
Most stalled pilots trace back to one of three patterns. We see all three, but rarely in the proportions executives expect.
Data readiness
Gartner reports that 85% of AI projects fail due to data quality, scope, or readiness issues — fragmented sources, missing labels, no governance over which fields can be trusted in production. This is the failure mode executives expect, and the one that's easiest to fund a fix for. It's also the one that gets named when the underlying problem is something else. The fix here is usually less about model tuning and more about the data maturity work underneath.
Workflow mismatch
The pilot works in isolation. It does not fit how the team operates on a Tuesday. No one mapped who looks at the output, when, and what behavior changes as a result. The model produces something useful and it lands in nobody's queue. This is the most common cause of stall and the most commonly misdiagnosed.
Governance and trust
Security flagged the data access pattern. Compliance hasn't signed off on the audit trail. Legal wants to see the hallucination rate before customer-facing deployment. The pilot is technically working but politically frozen. McKinsey's 2025 State of AI found that governance and risk management are the top areas where high-performing organizations differ from the rest. That difference shows up most painfully at the production handoff.
We ask one question to get past the executive's existing theory: Of data, workflow, and governance — which one do buyers misdiagnose most? The answer, by a wide margin, is workflow. Workflow problems disguise themselves as data problems because data problems have a clearer work ticket attached. "We need a better model" or "we need to clean up our data lake" almost always points to the artifact, not the operating model around it.
The first move in any rescue engagement is to break the team's existing story about what went wrong. We do that with a single question:
Walk me through the specific Tuesday afternoon when this pilot saves the team twenty hours.
If the team can describe that moment in detail — who is at their desk, what they're doing now, what changes when the AI output arrives — the pilot has an outcome. If they can't, the pilot was built to check an "we're doing AI" box, and no amount of model tuning will move it into production.
From there, we work the pilot through a structured evaluation across four dimensions. These are the questions we work through together with the team — not a branded framework, just the layers we've found have to be diagnosed in order before the rescue plan makes sense.

A pilot stuck at the first layer is a clarity problem. A pilot stuck at the second is a foundation problem. A pilot stuck at the third is a change-management problem. A pilot stuck at the fourth is an organizational problem. Each requires a different rescue plan, and conflating them is how teams burn another quarter on the wrong fix.
Before the engagement starts, we ask the executive sponsor to answer five questions. Three are organizational. Two are technical. The order matters.
If you can't answer three of the five with specifics, the bottleneck is clarity. The technical questions come last on purpose. Most teams expect them first, and that's the misdiagnosis.
Thirty days is enough to know which call to make. It is not enough to rebuild a production system, and it should not try. Here is how we structure the four weeks.
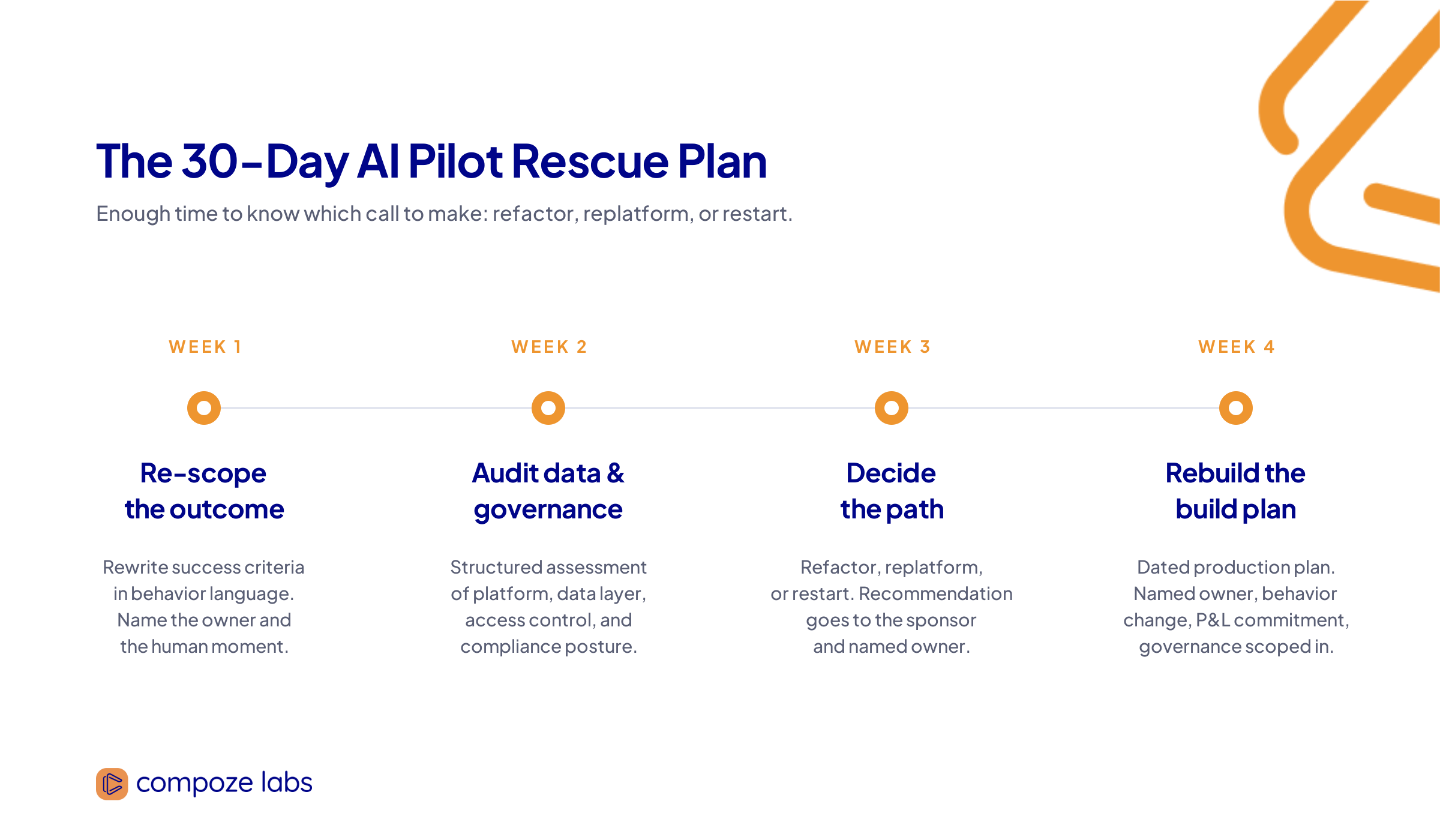
Week 1: Re-scope the outcome
The team rewrites the pilot's success criteria in behavior language, not capability language. Output of week 1 is a one-paragraph description of the specific human moment the AI changes, the metric that moves when it works, and the named owner whose P&L line is on the hook. In practice, week 1 is a series of working sessions with the original sponsor, the technical lead, and the end user the pilot was supposed to serve. If those three people can't be put in a room together, that itself is the finding.
Week 2: Audit data readiness and governance
The technical team runs a structured assessment against the platform, the data layer, and the access-control model. The question is not "does the model work" — it's whether what sits underneath the model is ready for enterprise traffic. This is also where security, compliance, and legal get pulled in for an early-stage risk read so the rollout doesn't stall again at the governance gate.
Week 3: Decide — refactor, replatform, or restart
The diagnostic findings get presented to the executive sponsor and the named owner. The recommendation is one of three calls. Refactor if the foundation is sound and the workflow needs to be rewired. Replatform if the model is appropriate but the data and platform layer cannot support production traffic. Restart if the original use case was scoped to the wrong outcome and the pilot would need to be rebuilt to mean anything.
Week 4: Rebuild the pilot plan with a production deadline
The output of week 4 is a dated production plan with a named owner, a defined behavior change, a P&L commitment, and the governance work scoped into the build rather than bolted onto the end. The deliverable is not a slide deck. It is a build plan a team can start executing on Monday.
The instinct for a six-figure sunk cost is to retool. Most teams do not need permission to retool — they need permission to restart, and they are not getting it because the original budget has a name attached to it.
The decision is simpler than the politics around it. Retool when the technical foundation is sound but the fit is wrong — the model works, the data layer is reasonable, and the workflow integration is the unfinished piece. Restart when the data or use case is fundamentally mismatched to what the business needed, or when the original sponsor has moved on and the new owner has a different outcome in mind.

The tell most buyers miss: the original executive sponsor has gone quiet or changed roles. Pilots without a live owner do not get retooled into success. They get re-scoped into something the new owner cares about, which is functionally a restart whether anyone calls it that. The second tell: the team cannot answer "who is the user and what changes for them" in one sentence. Restart is a clarity-of-outcome call.
A note on sunk-cost bias. The six figures already spent are not coming back. The question is whether the next six figures fund a build that ships or a refactor that delays the decision another quarter.
Most pilots deliver a working model in a notebook. Production-ready means something different. It means the model, the data layer underneath it, the workflow it lives inside, and the governance around it are all engineered to run without the original build team in the room.
One Compoze engagement makes the point. A client came to us with a stalled AI chatbot — they had spent months trying to put a personalized assistant on top of their existing enterprise data, and it wasn't landing. Week 1, we proved the model wasn't the problem. The platform underneath could not reliably surface what the AI needed to retrieve, and the data itself was not structured to be retrieved. Week 4, the deliverable was not a smarter chatbot. It was a rebuilt content and data layer that gave the AI something it could trust. The enterprise AI assistant shipped in the next phase, on the foundation we had just laid.
The pilot was not stalled on intelligence. It was stalled on what had not been built underneath it. Production-ready means you have built the underneath.
We start with a two-week diagnostic sprint inside our AI consulting and implementation practice, structured around the four-layer evaluation above. The deliverable is a decision-ready recommendation: refactor, replatform, or restart, with the build plan to match.
We are not the first call most executives make. Usually the first call is to the original build team to ask for one more sprint. We tend to come in after that sprint has not changed the answer. The diagnostic is built for that moment — when budget pressure is mounting and the path forward needs to be defensible to a board.
If your AI pilot is stuck six months in, the work is to figure out whether you have a foundation problem, a workflow problem, or a clarity problem before you spend another quarter solving the wrong one.


Count your active AI pilots. In the organizations we walk into, the number is usually somewhere between 15 and 30. Now name one workflow that runs...

You've been asked to fund AI. You don't have a CTO. And every research report you've opened so far is written for people who already know the...

Two years ago, most teams were using AI to speed up tasks they already knew how to do. Autocompleting code. Drafting emails. Summarizing documents....